

Scale AI’s RaR Method: Revolutionizing AI Reasoning
The field of Artificial Intelligence continues its relentless march forward, pushing boundaries and reshaping industries. While AI’s predictive capabilities have achieved remarkable feats, a persistent challenge has been its ability to perform complex, nuanced reasoning, especially in high-stakes domains like medicine and scientific research. Traditional AI training methods often struggle when the “right” answer isn’t a simple binary choice but rather a spectrum of contextual, multifaceted judgments. This is precisely where Scale AI’s groundbreaking Reasoning and Refinement (RaR) method emerges as a significant breakthrough, promising to unlock new levels of AI competence in these critical areas.
Key Takeaways
- Scale AI’s RaR method introduces a novel approach to AI training, moving beyond simple accuracy metrics to embrace nuanced, rubric-based evaluation.
- It enables AI models to “think like a teacher,” evaluating performance across multiple criteria rather than just a pass/fail outcome.
- RaR has demonstrated superior performance in complex medical reasoning (HealthBench-1k) and scientific reasoning (GPQA-Diamond) tasks, scaling effectively across various model sizes.
- This method enhances AI interpretability by using explicit rubrics, making the training process more transparent—a crucial factor for high-stakes applications.
- The RaR framework represents a philosophical shift in AI training, acknowledging the complexity of real-world problems and the sophistication of human judgment.
What is the RaR Method?
At its core, Scale AI’s RaR method, short for “Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains,” redefines how AI systems learn and are evaluated in complex scenarios. Unlike conventional reinforcement learning from human feedback (RLHF), which can oversimplify nuanced judgments into basic preference rankings, RaR introduces a structured, multi-dimensional assessment approach. Instead of merely asking “Is this answer correct?”, RaR prompts the AI to consider “How well does this answer address the key evaluation criteria?”
This innovative method draws an analogy to a teacher grading an essay. A teacher doesn’t just mark an essay as “good” or “bad”; they use a detailed rubric to evaluate various aspects like argument clarity, evidence usage, writing quality, and originality. Each dimension receives its own score, and the final grade reflects performance across all criteria. RaR applies this same principle to AI training, preserving the multifaceted nature of quality assessment while still providing clear, actionable signals for learning.
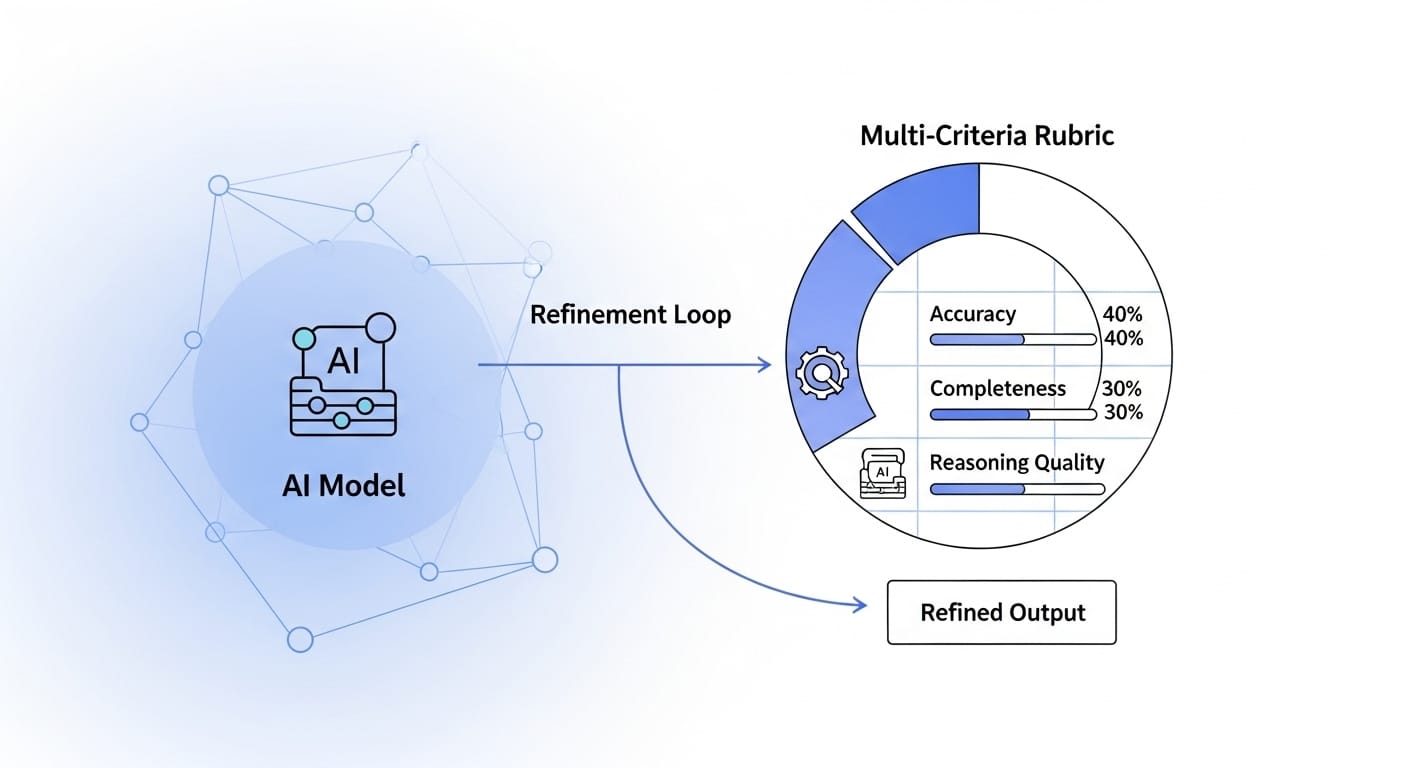
How RaR Works: The Mechanics
The technical elegance of RaR lies in its ability to generate and utilize these detailed rubrics. The framework leverages multiple evaluation criteria and then employs these structured assessments to train AI policies through advanced algorithms like Group Relative Policy Optimization (GRPO). This means that instead of a simplistic reward function, the AI receives granular feedback. For instance, in a medical context, feedback might include scores for “Diagnostic Accuracy,” “Differential Diagnosis,” and “Evidence Integration,” each with specific comments.
This granular feedback allows for significantly more sophisticated learning than traditional approaches. It moves beyond binary thinking, enabling AI systems to understand the nuances and contextual factors that define a truly “good” answer in complex domains. The transparency offered by explicit rubrics is invaluable, especially in fields where trust and interpretability are paramount. This shift from verification to nuanced evaluation is a fundamental change, helping AI understand what makes an answer good, not just if it’s correct.
Applications in Medical AI
The implications of the RaR method for medical AI are nothing short of revolutionary. Medicine is a field characterized by uncertainty, complex decision-making, and the need for nuanced judgment. Traditional AI models, with their often-binary outputs, have struggled to fully capture this complexity. RaR offers a path forward by training AI to provide nuanced medical advice that considers patient safety, differential diagnoses, and communication quality, not just diagnostic accuracy.
For example, in clinical practice, a patient’s symptoms might suggest multiple valid diagnoses, each requiring different levels of concern and follow-up. An AI trained with RaR could be evaluated on how well it navigates these ambiguities, integrates diverse clinical findings, and communicates potential treatment approaches. This capability is critical for developing AI tools that can truly augment healthcare professionals, improving diagnostic reasoning and patient care. Companies like Scale AI are at the forefront of powering cutting-edge AI solutions, including those for healthcare, by providing the high-quality training data and evaluation necessary for such sophisticated applications.
The ability to provide systematic, transparent, and verifiable reasoning is a cornerstone of clinical practice, and RaR directly addresses this critical gap in current LLMs used in medicine. This kind of advanced reasoning capability is essential for the future of healthcare AI, as highlighted in discussions around game-changing AI tools to watch in 2025.
Impact on Scientific Discovery
Beyond medicine, the RaR method holds immense promise for accelerating scientific discovery. Scientific research often involves formulating hypotheses, designing experiments, analyzing complex datasets, and drawing conclusions that may not have a single, definitive “correct” answer. Instead, scientific reasoning demands logical consistency, evidence integration, and the ability to explore multiple possibilities.
RaR’s capacity for nuanced evaluation can train AI systems to excel in these areas. Imagine an AI assisting in drug discovery, not just by predicting molecular interactions, but by reasoning through potential side effects, considering different biological pathways, and evaluating the strength of supporting evidence for each hypothesis. Similarly, in fields like materials science or astrophysics, AI could be trained to analyze vast amounts of data and generate novel insights, with its reasoning process being evaluated on criteria like novelty, feasibility, and explanatory power. The method has consistently outperformed traditional approaches in scientific reasoning tasks, demonstrating improvements that scale with model size.

Challenges and the Road Ahead
While the RaR method represents a significant leap, it is not without its challenges. The quality and effectiveness of the rubrics depend heavily on human expertise and careful design. Crafting comprehensive and unbiased rubrics for every complex domain requires significant effort from domain experts. However, the interpretable nature of RaR’s evaluation criteria makes it easier for experts to understand, refine, and iterate on these rubrics, fostering a continuous improvement loop.
The broader lesson from RaR is a call to action for AI practitioners: to shift from asking “How do we make AI give the right answer?” to “How do we help AI understand what makes an answer good?” This philosophical shift will be crucial as AI systems become increasingly integrated into high-stakes decision-making processes, demanding not just accuracy but also transparency, reliability, and ethical considerations. The development of more robust evaluation methodologies, like RaR, is vital for building trust in AI, particularly in sensitive areas like healthcare.
The Broader Implications for AI Training
The RaR method signals a broader trend in AI development towards more sophisticated and human-aligned training paradigms. As AI systems tackle increasingly complex and ambiguous tasks, the need for training methods that can capture the nuances of human judgment becomes paramount. This aligns with the evolving landscape of AI, where concepts like agentic AI and autonomous systems are gaining traction, requiring models that can not only execute tasks but also reason, adapt, and refine their approaches based on comprehensive feedback.
The focus on structured evaluation and interpretable feedback offered by RaR provides a blueprint for developing more trustworthy and capable AI across various sectors. It underscores the importance of human-in-the-loop approaches, where expert human knowledge is scaled rather than replaced, leading to AI systems that are both powerful and responsible.
Conclusion
Scale AI’s RaR method marks a pivotal moment in the evolution of AI training, especially for domains demanding sophisticated reasoning and nuanced judgment. By moving beyond simplistic evaluation metrics to embrace detailed, rubric-based feedback, RaR empowers AI models to achieve unprecedented levels of competence and interpretability in critical fields like medicine and scientific research. This breakthrough not only accelerates the development of more reliable AI but also fosters greater trust and transparency in its applications. As businesses navigate the complexities of advanced AI, leveraging expert AI solutions and technology consulting becomes paramount. Explore how our cutting-edge AI solutions, content marketing strategies, and technology consulting can empower your next innovation and growth.

